
Google DeepMind
Most of the activities that go on inside cells—the activities that keep us living, breathing, thinking animals—are handled by proteins. They allow cells to communicate with each other, run a cell’s basic metabolism, and help convert the information stored in DNA into even more proteins. And all of that depends on the ability of the protein’s string of amino acids to fold up into a complicated yet specific three-dimensional shape that enables it to function.
Up until this decade, understanding that 3D shape meant purifying the protein and subjecting it to a time- and labor-intensive process to determine its structure. But that changed with the work of DeepMind, one of Google’s AI divisions, which released Alpha Fold in 2021, and a similar academic effort shortly afterward. The software wasn’t perfect; it struggled with larger proteins and didn’t offer high-confidence solutions for every protein. But many of its predictions turned out to be remarkably accurate.
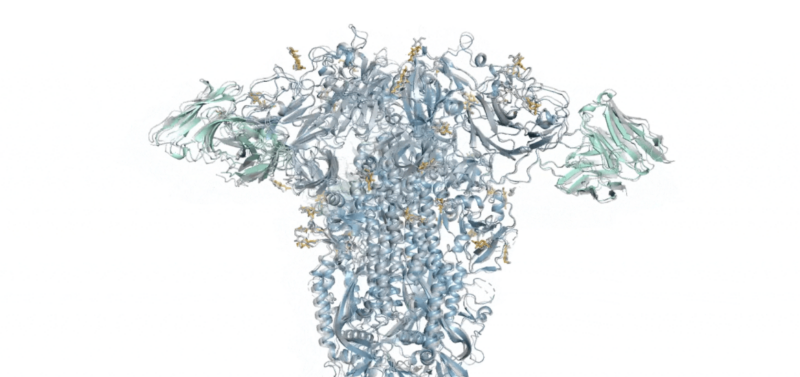
Even so, these structures only told half of the story. To function, almost every protein has to interact with something else—other proteins, DNA, chemicals, membranes, and more. And, while the initial version of AlphaFold could handle some protein-protein interactions, the rest remained black boxes. Today, DeepMind is announcing the availability of version 3 of AlphaFold, which has seen parts of its underlying engine either heavily modified or replaced entirely. Thanks to these changes, the software now handles various additional protein interactions and modifications.
Changing parts
The original AlphaFold relied on two underlying software functions. One of those took evolutionary limits on a protein into account. By looking at the same protein in multiple species, you can get a sense for which parts are always the same, and therefore likely to be central to its function. That centrality implies that they’re always likely to be in the same location and orientation in the protein’s structure. To do this, the original AlphaFold found as many versions of a protein as it could and lined up their sequences to look for the portions that showed little variation.
Doing so, however, is computationally expensive since the more proteins you line up, the more constraints you have to resolve. In the new version, the AlphaFold team still identified multiple related proteins but switched to largely performing alignments using pairs of protein sequences from within the set of related ones. This probably isn’t as information-rich as a multi-alignment, but it’s far more computationally efficient, and the lost information doesn’t appear to be critical to figuring out protein structures.
Using these alignments, a separate software module figured out the spatial relationships among pairs of amino acids within the target protein. Those relationships were then translated into spatial coordinates for each atom by code that took into account some of the physical properties of amino acids, like which portions of an amino acid could rotate relative to others, etc.
In AlphaFold 3, the prediction of atomic positions is handled by a diffusion module, which is trained by being given both a known structure and versions of that structure where noise (in the form of shifting the positions of some atoms) has been added. This allows the diffusion module to take the inexact locations described by relative positions and convert them into exact predictions of the location of every atom in the protein. It doesn’t need to be told the physical properties of amino acids, because it can figure out what they normally do by looking at enough structures.
(DeepMind had to train on two different levels of noise to get the diffusion module to work: one in which the locations of atoms were shifted while the general structure was left intact and a second where the noise involved shifting the large-scale structure of the protein, thus affecting the location of lots of atoms.)
During training, the team found that it took about 20,000 instances of protein structures for AlphaFold 3 to get about 97 percent of a set of test structures right. By 60,000 instances, it started getting protein-protein interfaces correct at that frequency, too. And, critically, it started getting proteins complexed with other molecules right, as well.